目的
对齐对风控智能体的理解(认识+代码),确认未来开发方向和人力分工。
1. 什么是智能体(AI Agent)?
1.1 智能体的通俗解释
**智能体就像是一个”聪明的助手”**,它能够:
- 理解问题:听懂用户的需求和意图
- 使用工具:像人一样调用各种系统和工具来解决问题
举例:
我想写个贪吃蛇游戏:

大模型会告诉你代码,以及怎么运行,但是大模型没法帮我们实际写文件和执行代码。
可以理解为,大模型就是大脑,没有手和脚。
智能体(AI Agent)作用就是赋予大模型使用外部工具和改变外部环境的能力。
也就是说,智能体给了大模型手和脚。
1.2 如何做到呢?
智能体的核心原理其实很简单:我们预先准备好一些工具方法,然后通过特定的Prompt格式,让大模型学会调用这些工具来完成任务。
具体来说,就是让大模型以我们规定的JSON格式返回”思考”和”行动”,然后我们的系统解析这些行动并执行相应的工具。
简单示例演示
假设我们要让AI帮我们写一个贪吃蛇游戏,我们首先要实现将代码写入本地文件的能力,因此,我在 AI Agent 里实现了对应的 write_file(file_name, file_content string) 工具方法:
sequenceDiagram
participant 用户
participant AI Agent
participant 大模型
participant 工具系统
用户->>AI Agent: "帮我写个贪吃蛇游戏"
AI Agent->>大模型: 发送Prompt(包含工具说明)
大模型->>AI Agent: 返回JSON格式响应
Note over 大模型: {"thought": "需要创建游戏文件", "action": "write_file('snake.py', 'import pygame...')"}
AI Agent->>工具系统: 解析并执行action
工具系统->>AI Agent: 执行结果("文件写入成功")
AI Agent->>大模型: 将结果作为observation发送
大模型->>AI Agent: 返回最终结论
AI Agent->>用户: "贪吃蛇游戏已创建完成"
实际交互过程


上面的 “写入完成” 是我模拟AI Agent的返回。在实际的AI Agent系统中,会先执行 action 模块中的工具调用,然后将执行结果反馈给大模型,如果是复杂任务,会有多次这样的往复交互。
核心实现逻辑
因此,基于上面的Prompt格式来构建智能体,我们的AI Agent只需要做一件事:不断与大模型交互,解析返回JSON中的 action 字段,执行相应工具,直到大模型返回 <end> 标签表示任务完成。
2. midas-rc 智能体的具体实现
2.1 整体流程
整体流程比较清晰。
graph TD
A[用户HTTP请求<br/>我想分析王者荣耀的代充风险] --> B[tRPC-Go Server<br/>:8010端口]
B --> D{智能体类型?<br/>req.AgentId}
D -->|AgentChatModelApp| E[通用聊天智能体<br/>直接调用LLM返回]
D -->|AgentMidasRCAnalysis| F[数据分析智能体ReactAgentAnalysis]
%% 数据分析智能体流程
F --> G[获取Prompt]
G --> L[调用大模型,完成分析计划]
L --> Q[返回Answer给用户]
%% 流式输出
E --> S1[SSE流式推送<br/>用户看到回答]
Q --> S1
因此可以看到,核心要素其实是在Prompt的生成。
可以看一个更加详细的流程图来了解 Prompt 的生成方式:
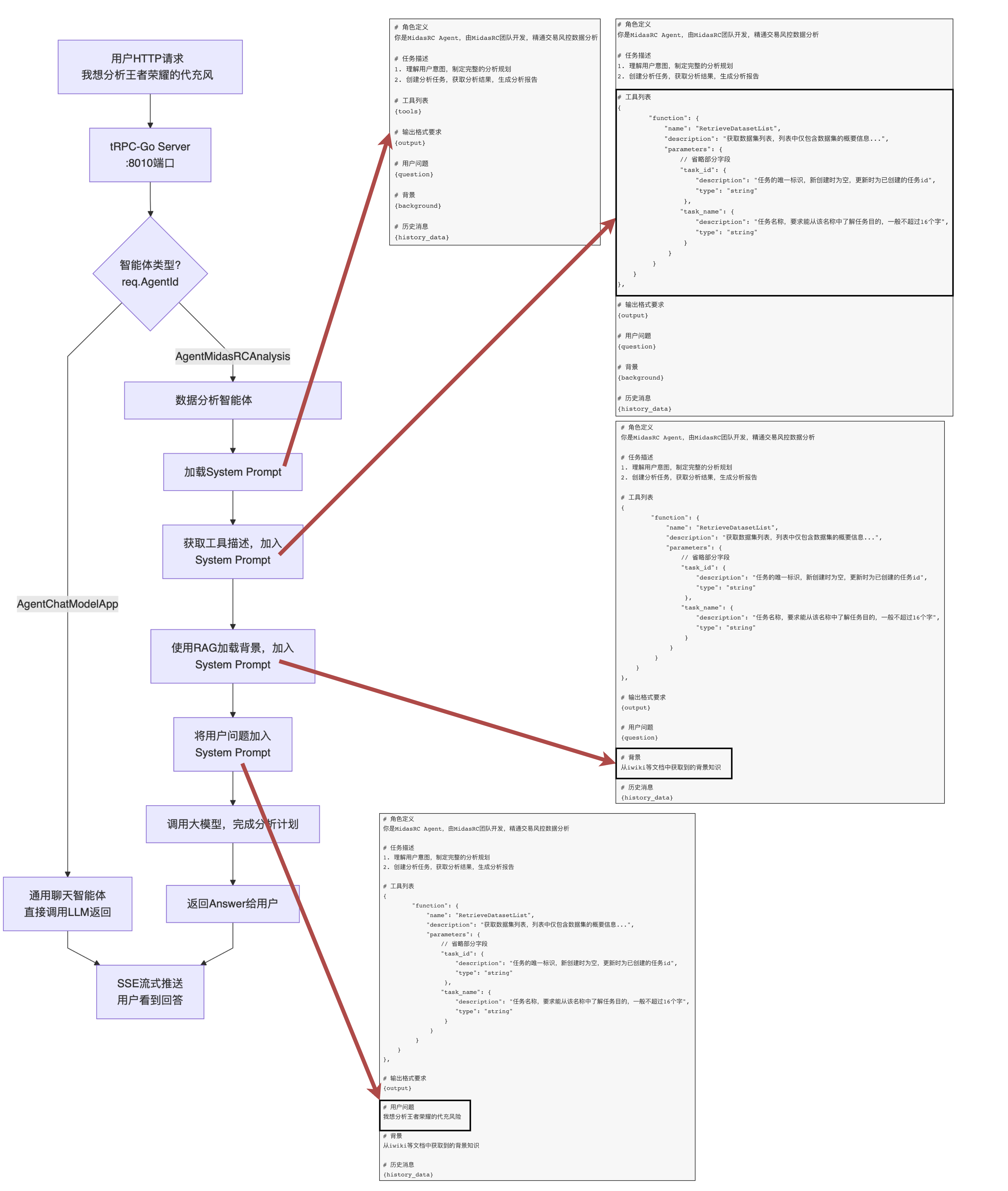
上面做的事情是为了让模型明白背景,知道工具怎么使用。
但是,在和大模型打交道的时候,我们常常会发现,光给它一个问题,它不一定能立刻抓住重点、给到我们想要的答案。所以有一个更关键的问题:我们该如何向大模型提问,才能让它沿着合适的思路,帮我们更快、更高效地分析问题?
答案就是在Promt里,严格限定他的分析思路和分析架构,在midasrc中,是用输入输出格式要求这部分,严格规定了分析思路,来看下目前我们系统具体怎么实现的:
1 | |
2.2 分析架构
A. 系统实现方式
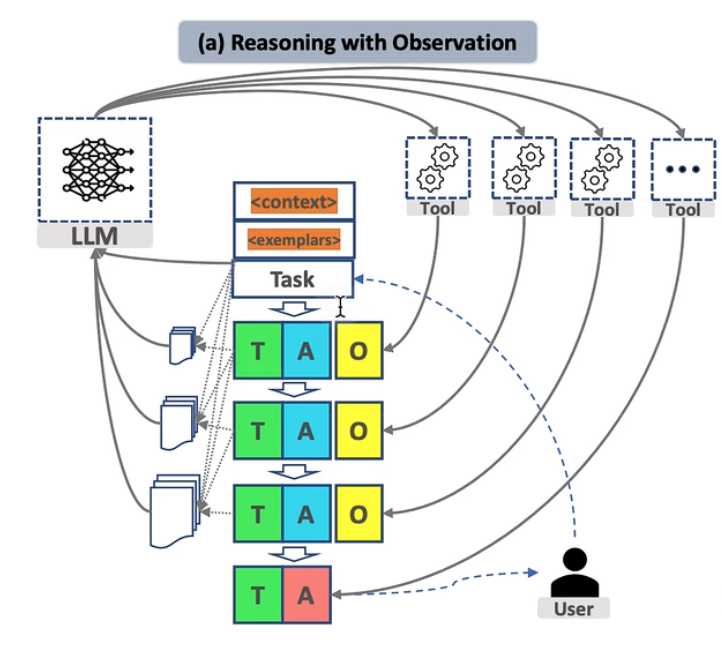
项目目前采用的是 ReAct (Reasoning + Acting) 模式,这是目前最成熟的智能体架构之一,让我们和模型之间的交互符合以下的模式:
1 | |
核心技术实现细节,如何实现ReAct?
1. 精细化的Prompt工程
在 prompt中,通过严格规范输入和输出形式,让模型以ReAct模式和我们进行交互。
具体来说,Agent 需要在 Prompt 中规定大模型给我们的返回中必须有 Thought(思考),Action(行为),我们执行 Action,将结果封装进 Observation(观察)中,让模型决策,是继续执行其他 Action,还是直接结束给出 Conclusion(结论)。
以 midas-rc 智能体的具体 Prompt为例:
在这里,Agent 在 Prompt 中通过严格规范输入输出,实现了 ReAct 模式的交互。
实际案例展示
sequenceDiagram
participant 用户
participant AI Agent
participant 大模型
participant 工具系统
Note over 用户,工具系统: 第1轮 ReAct循环
用户->>AI Agent: "我想分析代充风险"
AI Agent->>大模型: 发送Prompt(包含工具说明和用户问题)
大模型->>AI Agent: {"thought": "需要先了解有哪些数据集可用", "action": "RetrieveDatasetList"}
AI Agent->>工具系统: 解析并执行RetrieveDatasetList工具
工具系统->>AI Agent: 返回15个数据集列表
AI Agent->>大模型: 将结果作为observation发送
Note over 用户,工具系统: 第2轮 ReAct循环
大模型->>AI Agent: {"thought": "根据代充风险分析需求,选择游戏交易明细表最合适", "action": "RetrieveDatasetDetail"}
AI Agent->>工具系统: 解析并执行RetrieveDatasetDetail工具
工具系统->>AI Agent: 返回表结构信息(user_id, game_id, pay_amount等)
AI Agent->>大模型: 将结果作为observation发送
Note over 用户,工具系统: 第3轮 ReAct循环
大模型->>AI Agent: {"thought": "现在可以创建分析流程,重点关注异常充值模式", "action": "CreateAnalysisFlowProcedure"}
AI Agent->>工具系统: 解析并执行CreateAnalysisFlowProcedure工具
工具系统->>AI Agent: 创建成功,返回procedure_id: "proc_12345"
AI Agent->>大模型: 将结果作为observation发送
Note over 用户,工具系统: 最终结论
大模型->>AI Agent: {"thought": "分析流程已建立完成", "conclusion": "代充风险分析流程已成功创建,包含异常充值模式检测..."}
AI Agent->>用户: "代充风险分析流程已建立完成,您可以开始执行分析任务"
关键特点:
- 循环往复:思考→行动→观察→思考→行动…
- 单步执行:每次只执行一个工具调用
- 持续学习:通过观察结果不断调整下一步行动
- 智能终止:当任务完成时给出最终结论
问题
当前只支持ReAct分析架构,在分析简单问题的时候,快速高效,但是在遇到复杂问题的时候,难免会有些局限。
在此之前,我们先了解一下当前主流的分析架构
三种主流架构对比
场景:用户问”帮我分析最近一个月王者荣耀和和平精英的充值异常情况”
A. ReAct方式(我们现在的实现)
每次只执行一个任务,如果需要执行10个任务,就需要和大模型交互10次。
当前代码实现:
1 | |
优点:实现简单,易于调试,错误恢复能力强
缺点:无法并行处理,单次只会执行一个任务,会和模型有大量交互,token量和速度都较难支持
对于水文平台,如果我要分析交易量上涨,那么需要分析多种聚集情况,例如用户聚集,muid聚集,物品聚集,渠道聚集,业务聚集,币种聚集,如果串行执行,时间很长且需要和大模型交互次数会非常多。
因此,有一种更加适合我们的方式,叫Plan-And-Execute模式。
B. Plan-And-Execute方式
顾名思义,Plan-And-Execute是先给出一个执行计划,这个执行计划不是和ReAct的Action一样一次只能执行应该给方法,而是给出所有需要执行的任务,让执行器去一次性执行完成,执行完成之后,再根据获得的结果确认是否需要再次 Replain,还是可以直接给出结论了。
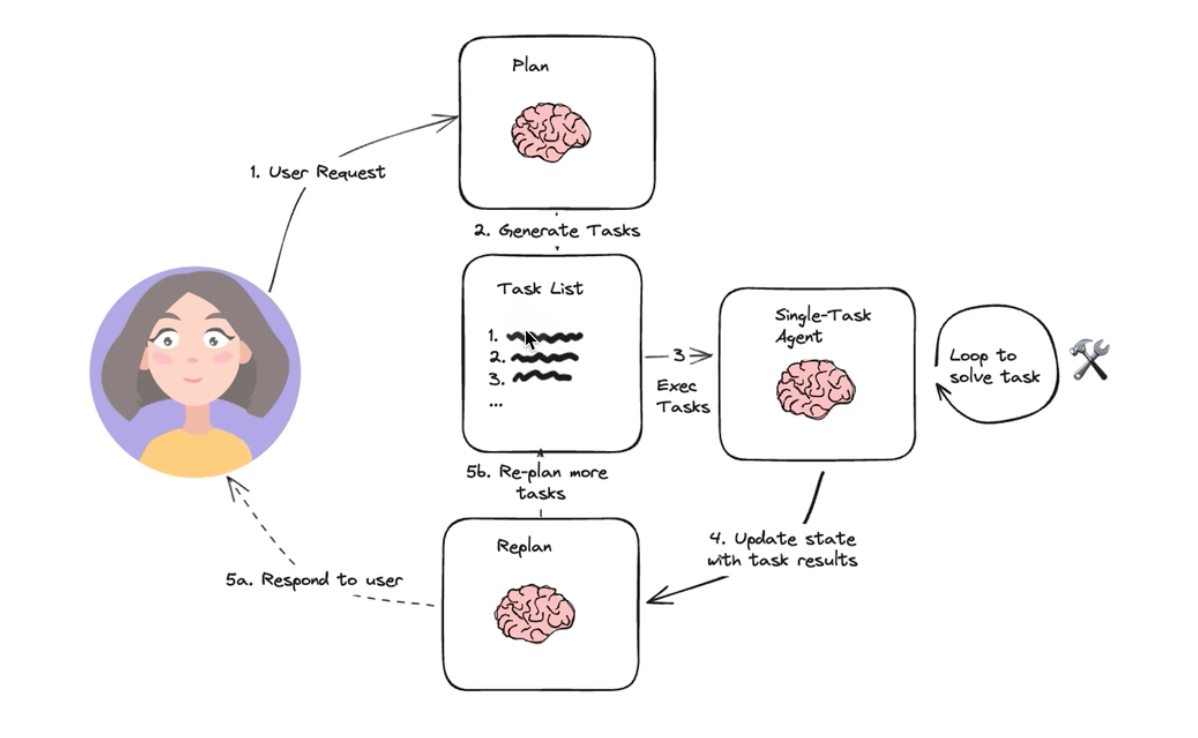
理想代码架构:
1 | |
1 | |
优点:执行高效,规划清晰,适合复杂多步骤任务
缺点:规划固定,难以处理动态变化的情况
C. ReWoo方式
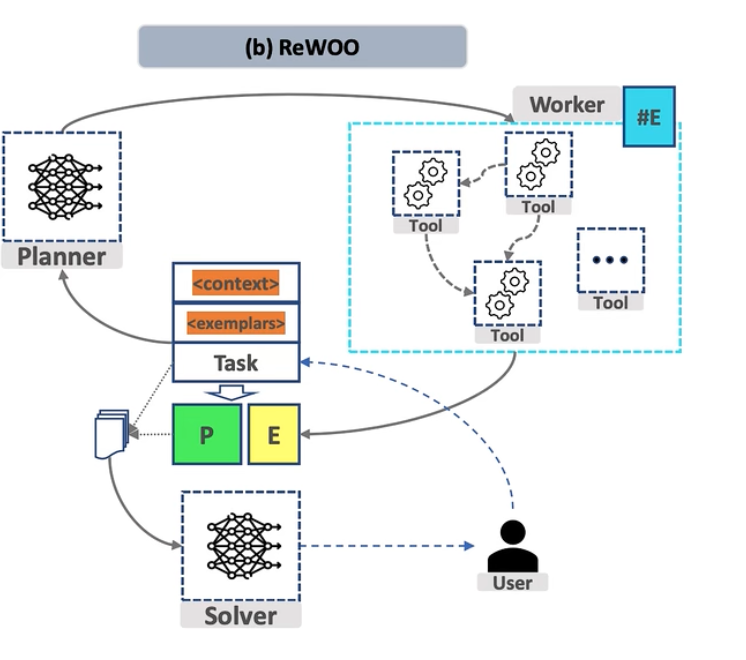
理想代码架构:
1 | |
优点:并行度极高,工具调用效率最优,适合I/O密集任务
缺点:实现复杂,错误处理困难,需要精确的工具依赖分析
我们应该选择哪种?
2.3 工具系统
系统集成
工具是放在 Promt 之中,让模型之后你的系统有哪些工具,工具有什么效果,应该怎么使用这些工具。

系统实现方式
目前实现了9种工具,通过硬编码注册到Agent中
硬编码工具注册
每个工具都需要实现tool.BaseTool接口
1 | |
实际工具实现示例:获取数据集列表工具
1 | |
效果
1 | |
问题
A. 每个工具需要大量样板代码,开发效率不高
新增一个工具的完整流程:
- 定义Go结构体和参数schema
- 实现Info方法
- 实现InvokableRun方法
- 实现StreamableRun方法
- 添加到工具列表
- 重新编译部署
B. 功能扩展受限
当前能力边界:
- 只能做数据分析相关的9个操作
- 无法操作文件系统
- 无法发送邮件
- 无法调用其他AI服务
- 无法进行网页抓取
解决方案
提供集成MCP协议的能力
MCP协议详解
MCP服务器的本质
MCP服务器本质上就是一个普通的服务,它实现了具体的工具方法(如文件操作、网络请求、数据库查询等),额外提供了一个标准的/tools/list接口,这个接口返回了对这些工具方法的具体描述,让外界能够发现和了解这些工具的使用方法。
MCP协议在智能体中的工作位置
在深入MCP协议细节之前,让我们先了解MCP协议在整个智能体系统中的工作位置:
sequenceDiagram
participant 用户
participant AI Agent
participant MCP服务器
participant 大模型
Note over 用户,大模型: MCP服务注册阶段
AI Agent->>MCP服务器: GET /tools/list
MCP服务器->>AI Agent: 返回工具列表JSON
Note over AI Agent: 解析工具列表,构建{tools}内容
Note over 用户,大模型: 用户交互阶段
用户->>AI Agent: "我想分析代充风险"
AI Agent->>大模型: 发送完整Prompt(包含{tools}内容)
大模型->>AI Agent: 返回JSON格式响应
AI Agent->>MCP服务器: 根据大模型决策调用具体工具
MCP服务器->>AI Agent: 返回工具执行结果
AI Agent->>大模型: 将结果作为observation发送
大模型->>AI Agent: 返回最终结论
AI Agent->>用户: 返回分析结果
关键理解:
- 工具发现阶段:AI Agent通过MCP协议动态获取可用工具列表
- Prompt构建阶段:将获取的工具信息填充到{tools}占位符中
- 智能交互阶段:大模型基于完整的工具信息进行决策和执行
多MCP服务器场景
在实际应用中,通常会有多个MCP服务器,每个服务器提供不同领域的工具:
graph TD
A[AI Agent] --> B[文件操作MCP服务器<br/>:8080端口]
A --> C[网络请求MCP服务器<br/>:8081端口]
A --> D[数据库查询MCP服务器<br/>:8082端口]
A --> E[AI服务MCP服务器<br/>:8083端口]
B --> B1[write_file<br/>read_file<br/>delete_file]
C --> C1[http_request<br/>send_email<br/>web_scrape]
D --> D1[query_database<br/>get_table_info<br/>execute_sql]
E --> E1[call_llm<br/>image_generate<br/>text_analyze]
style A fill:#e3f2fd
style B fill:#fff3e0
style C fill:#fff3e0
style D fill:#fff3e0
style E fill:#fff3e0
多服务器工作流程:
- 启动阶段:AI Agent向所有MCP服务器发送
/tools/list请求 - 工具聚合:收集所有服务器的工具列表,合并到统一的{tools}内容中
- 智能调用:大模型根据任务需求,智能选择最合适的工具进行调用
- 动态扩展:可以随时添加新的MCP服务器,无需修改AI Agent代码
核心工作原理
MCP协议的核心思想是:工具提供者只需要实现具体的功能方法,MCP框架会自动生成标准的工具描述接口。
具体实现示例
假设我们要提供Google和百度搜索工具,传统方式需要大量样板代码,而使用MCP协议只需要:
1 | |
MCP框架自动完成的工作:
- 自动生成
tools/list接口 - 自动解析函数签名和参数类型
- 自动生成工具描述文档
- 提供标准的JSON-RPC协议接口
标准接口交互
当AI Agent需要发现可用工具时,会调用MCP服务的标准接口:
1 | |
MCP服务自动返回标准格式的工具描述:
1 | |
MCP协议的核心优势
1. 开发效率大幅提升
- 从90-120行样板代码 → 只需几行功能代码
- 自动生成工具描述和接口文档
- 无需手动维护工具注册逻辑
2. 标准化工具生态
- 统一的工具发现和调用协议
- 可以轻松集成第三方MCP服务
- 工具之间可以互相组合和复用
3. 动态工具加载
- 支持运行时添加/移除工具
- 无需重启智能体服务
- 支持工具版本管理和热更新
丰富的MCP工具生态
业界已经有很多成熟的MCP服务可以直接使用:
这些工具涵盖了文件操作、网络请求、数据库查询、AI服务调用等各个领域,大大扩展了智能体的能力边界。
2.4 会话记忆、状态管理方式
当前,会话记忆、状态管理都是自己实现。
背景
大模型是无状态的,每次请求都需要带上历史所有交互的信息和背景知识,不然大模型不知道我们在说什么。
系统实现方式
举例,看现在的单次调用:

和大模型的一次完整交互:
1 | |
问题:
- 随着会话逐渐变长,历史信息会越来越多,而且并不是所有历史信息都很重要,并且token会逐渐爆炸。
- 如果工具调用失败或者模型调用失败,具体应该怎么处理,都需要自己编程来解决,并且如果服务重启,所有信息全部丢失
解决方案
针对token越来越爆炸的问题,有很多种处理方案:
- 只携带最近几次交互给模型
- 总结之后的历史信息再给模型
- …
针对服务挂了所有信息全部丢失的情况,可以将每次交互都进行持久化,然后再获取,也需要编程实现。
这些方案如果都要我们自己实现,编程量不小,而且容易写错,所幸目前 tRPC-Go Agent 框架给了一些成熟解决方案,里面核心组件 Session 可以帮我们解决这些问题。

如果服务挂了,也可以通过 SessionId,自动获取持久化的历史记录,快速恢复服务,而不用重新和用户进行交互。
3 还需要开发的核心组件
A. 状态管理(历史会话处理)工具
功能: 让风控智能体具备更加智能处理上下文和状态管理的能力
B. MCP工具集成
功能:支持标准工具协议,动态加载外部工具
改造方案:
1 | |
C. 风控智能体针对通用场景改造
功能:让风控智能体适用其余场景,而非只能为 midas-rc 服务
D. 文档
需要有成熟的水文系统相关文档,以及合适的提示词
E. Plan-And-Execute智能体?
功能:实现规划-执行分离的智能体架构
F. ReWoo智能体?
功能:实现推理-工具分离的并行处理架构
G. 智能路由器?
功能:根据问题特征自动选择最佳智能体